引文
从这里开始,本文(算是连载文)打算从基础的概念去理解DDD,上文主要讲了DDD的概念和原则,今天就从基础名词和核心思想来理解它。
DDD的体系引入了很多名词,从解决问题的方向分为:领域、子域、核心域、通用域、支撑域、限界上下文,从建模的方向又分为:聚合、聚合根、实体、值对象等等,这些名词真的是晦涩难懂,虽然在工作实践中并不会说是需要抠这些字眼,但是学习了这些对我们理解DDD这一体系也是很有帮助的。
这里我们抛开这些名词,从软件设计的角度来从新认识这些名词的含义。
软件的核心目标?
《领域驱动设计》这本书中说:软件的核心是为用户解决“领域”相关的问题的能力。(其中我们先忽略 领域 这个词)软件的核心就是为用户解决相关问题,不管其他目标是否重要,所有的其他目标都是应该围绕着这个主题。
上文中提到了“领域”一词,领域在字典中直接翻译过来就是:领域是从事一种专门活动或事业的范围、部类或部门。当然,软件也是同理,在领域驱动设计DDD中,领域就是用来划分边界、范围的,而我们用户的领域相关问题:那么就是在用户当前上下文中,需要解决的业务问题,DDD中的领域通俗一点说,就是当前上下文(业务背景)下需要解决的问题域,比如电商系统中会有:“商品领域”、“物流领域”、“订单领域”、“库存领域”、“仓储领域”。
在用户的角度来看,通常有其关注的业务方向,比如我们之前做的“物流领域”,实现一个复杂的业务问题往往不是开发一个页面,加两三个接口就完成了,在这个“领域”内我们需要解决很多问题:权限、隐私、认证、公共配置等等众多子问题,都需要我们一一解决。在算法中,有一种思想叫做分而治之,优秀的思想总会被互相借鉴的。同理:这些子问题,在DDD中他们有一个共同的名字:子域,子域也叫“子领域”,就是我们将用户关心的业务问题,划分为多个模块的子问题,每个子模块对应一个子问题或者说是更小的业务范围,每一项技术并不能解决所有问题,但是将大问题拆分成更小的子问题过程中,我们就可以在我们技术的角度去解决当前的问题了。
(在大多数软件设计中,技术人员更多的是关注可量化的、可提高技能的技术问题,而对我们的问题的核心目标:核心领域知识 不是特别感冒,相反,其实软件的核心问题才是需要我们直接面对和解决的)
这里我们可以简单举一个例子,例如我们之前的拆分的物流中心,设计如下:
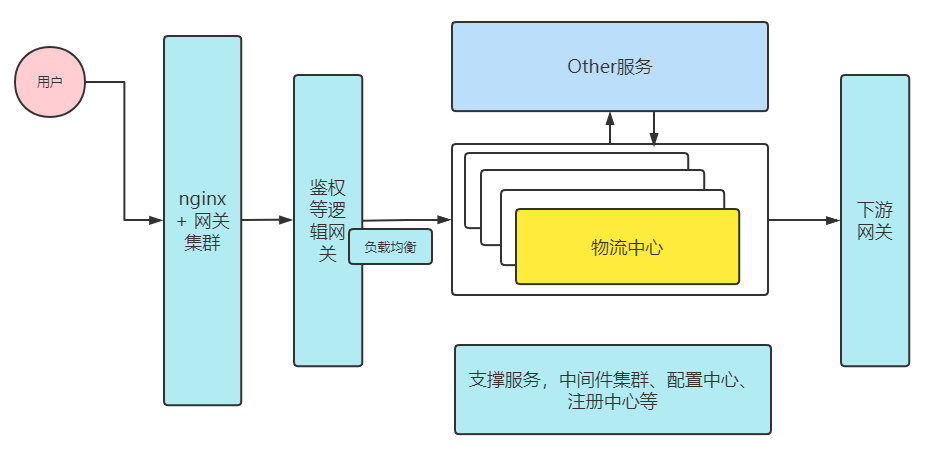
这里的架构图比较简单,它的业务价值是为企业快速接入通用的快递服务,目前它的主要运作模式为:
- 用户请求进来,网关鉴权
- 网络鉴权成功,获取注册信息进行负载均衡
- 物流中心服务内部进行逻辑处理,可能会经过调用其他服务拿取数据,最后转成需要的参数
- 物流中心将请求发出,经过下游网关将数据路由到(某山、或者某地承运商)下游服务
- 获得下游返回信息,将请求响应返回给用户
在这个模式中,我们会设计很多组件:网关、缓存中间件Redis、配置中心、注册中心nacos等,它们必须要存在,但是他们是可以替代的,比如注册中心nacos可以换成eureka,新增Apollo配置中心什么的,网关可以换成Spring Gateway
对于通用的网关、鉴权中心等等,这些都是软件需要解决的问题“子域”,但它们的本质是可以替代的,并且只需要完成某种特定的功能,为整个企业提供统一的服务,这些子域就是通用域,短期内我们还可以考虑使用更小的成本引入,比如外包、或者平台封装通用的组件等等;对于Other服务,我们需要通过http或者其他协议调用拿到我们业务想要的数据,比如订单信息等等,这些问题子域是支撑域,它具有一些企业的特性,但是不容易买到也没有通用的解决方案,需要涉及到定制开发;
当然,还有我们黄色部分:物流模块,它作为我们的核心业务方向,是我们最关注的部分,这一部分子域我们在领域驱动设计中也叫“核心域”,它们是我们业务的核心价值,决定着该应用的核心竞争力。
为什么DDD要划分:核心域、通用域和支撑域?
这个问题我觉得可以举曾经看到的一个案例,很多公司看上去是一样的,但是他们的商业模式和战略方向其实是有很大的差异的,比如淘宝、天猫、京东和苏宁易购,他们虽然都是电商产品,淘宝是一个C2C的网站,个人卖家对接个人买家,而天猫、京东和苏宁易购都是B2C网站,是公司卖家对个人买家。即便是苏宁易购与京东都是 B2C 的模式,他们的商业模式也是不一样的,苏宁易购是典型的传统线下卖场转型成为电商,京东则是直营加部分平台模式。
商业模式的不同会导致核心域划分结果的不同。有的公司核心域可能在客户服务,有的可能在产品质量,有的可能在物流。在公司领域细分、建立领域模型和系统建设时,我们就要结合公司战略重点和商业模式,找到核心域了,且重点关注核心域。
这里我们假设当前公司的业务领域是一个整体的方向,那么如果此时要做微服务拆分的话,其实就是业务逐渐扩张,完善的过程;在此时我们要拆解公司的业务“子域”,将公司的核心战略目标:“核心域”放在首位建设,有方向的朝着一个目标发展,在这个方向要有绝对掌控权和研发扩展能力,支撑域或者通用域方向可以适当放松,当然也可以考虑外包或者使用通用的方案等等。
这里可以小节一下,为什么要划分:核心域、通用域和支撑域,其实就是为了划分业务等级,分别对待,每个公司的人力和资源都是有限的,要在核心领域上发力是软件架构设计都需要和考虑的部分。
何为限界上下文?
前面我们说到DDD的核心设计原则是“统一语言”,那么对于一个业务系统,真的能够完全统一语言吗?
这里举一个真实的案例:假设一个电商系统里面,订单的业务后台微服务会根据前台用户提交的单据,将这个业务模型称作“订单”;而隔壁的仓储对接小组会根据每个需要打包发货的包裹,对下游承运商(比如:顺丰、中通、韵达等快递公司)安排取件,在这些仓储系统中和承运商的系统中,每一个包裹也会被称为“订单”,快递订单和前台用户下单的订单是一个订单吗?
中文语言博大精深,我们在说一句话时往往需要对方在我们处在同一个上下文(同一个环境中,这样才能确认大家理解是一致的)内,软件设计也是这样,员工刚入职的时候需要有人带着了解环境信息快速融入团队,CPU在线程切换时需要保存线程上下文信息...这些只是说我们在工作或者讨论问题时,需要一个环境上下文信息,仅此而已。
所以,在每个系统甚至一个系统中不同业务方向上的名词,是代表不同的含义的,此时,我们在关注的问题域上不能包含二义性的名字,因为这样会使我们的内部模型定义产生一些歧义。所以,我们在讨论业务领域统一语言时,需要一定的上下文,这个上下文的边界,我们称作限界上下文。限界就是领域的边界,而上下文则是语义环境。通过领域的限界上下文,我们就可以在统一的领域边界内用统一的语言进行交流。
如何划分限界上下文?
理解了限界上下文,我们再看在DDD中该怎么划分限界上下文呢?这个问题,也是划分领域边界的问题,往往需要结合问题的子域来看。
一个限界上下文封装了一个相对独立子领域的领域模型和服务。子域subdomain和限界上下文某种意义上是互相印证的
这句话很官方,意思就是说,我们需要解决的业务问题及问题子域,往往存在于一个划分限界上下文内(嗯?这个不是废话吗)。我的理解,这个只是我们的目标也是指导方向,那么如何划分限界上下文呢?
主要有以下几个步骤:
- 将事件风暴(后面会解释)分析出的全部领域名词都提取出来(规则:1.全面,包含外部系统 2.不重复),放在大白纸上(或者其他地方,能让大家看到就行)
- 将领域名词按照业务领域划分快速归类,外部系统单独放置
- 集体讨论,将这些名词中存在语言、业务、概念二义性的名词提取出来,标明他们存在的问题边界,消除他们二义性
上面只是建议的步骤方向,当然也不绝对可以按照自己团队的理解和安排自行调整。总之,小节一下就是:划分限界上下文的过程就是澄清二义性的过程,如果在不同的领域存在业务、概念、语言的二义性时,那么此时两个业务就需要一个限定,来限定二者概念的上下文
那划分实体、值对象的含义是什么?
看完了战略设计的问题划分,我们回到实体、值对象这两个词,这几个词存在于战术设计上,我们将视角下移,从代码层次来了解他们,学习聚合和聚合根之前,首先来了解一下实体和值对象。
实体、值对象
在 DDD 中我们关注领域对象,(领域对象就是我们的业务数据模型,这些数据对外服务构成了我们的系统,所以也叫数据系统),领域模型的存在模式有两种:实体和值对象。
我们一直在强调领域对象,那么领域对象是一种什么形式落地于我们的软件系统中呢?实际上就是实体,实体和值对象是组成领域模型的基础单元,比如用户的订单数据,我们可以在订单微服务中将订单设计为实体,它是我们的业务模型,往往有一个订单编号OrderNo来唯一标识是一个订单数据;用户中心的用户数据,用户也是一个业务模型我们也可以设计为实体,而他有一个叫做身份证编码的CardNo来唯一标识一个用户。实体存在于软件的领域模型中,主要是我们的业务载体,为了标识它,我们往往会根据业务定义一个唯一标识符来标识它。
(业务的唯一标识符不是数据库的Id,但数据库Id可以作为业务的唯一标识符存在,比如订单系统中的订单编码,订单编码存在的意义就是为了标识唯一的一个订单数据,而数据库存储了什么Id和业务没有本质的联系,这里要细节区分)
那么为什么要称为实体呢,充血模型和它什么联系?
这里我们仍然是一个问题导向的方式去学习。实际上,这两种并不冲突,充血模型是我们DDD的软件设计原则的细则,面向对象设计模型的一种方式,而实体是一种模型的定义,实体往往使用充血模型的方式去定义和实现业务逻辑。
值对象在《实现领域驱动设计》一书中是这么定义的:通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体。值对象在DDD中就是一堆属性的集合体,类似于我们的JavaBean,是数据中真正的载体。其实这里扣实体和值对象的区别有一点死扣概念了,因为我们的软件设计中,肯定是有一部分无关的业务模型,这一部分的业务模型不具有唯一标识但是有其服务业务的作用,可以是简单的属性,也可以是复杂的属性集合,比如订单微服务中的数据字典、地址的省市区等等。
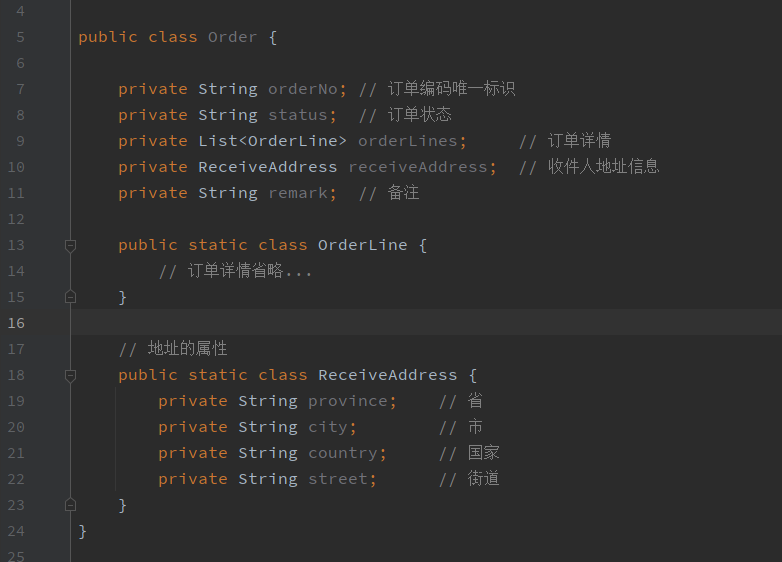
值对象可以拍平展示到实体中,也可以设计一个属性被实体引用,比如以下的模式
收件人的地址信息(值对象)被订单实体引用
亦或者是,直接拍平放在订单模型里
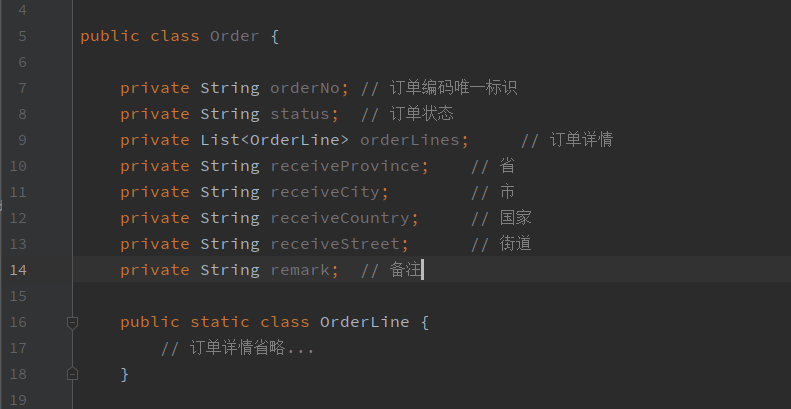
这里我们的备注信息,也可以是一个对象,然后被订单模型引用,怎么设计值对象是拍平还是一个对象的嵌套引用呢?
我认为是以下两个规则:
- 如果值对象的属性涉及重复的概念,建议设计成嵌套对象。比如发货单会存在:收件人和发件人的信息,那么此时设计成引用类型,用结构作区分最好,同时也可以复用结构
- 如果值对象的属性来源于外部系统,建议设计为嵌套对象。比如订单模型中的商品信息,如果平铺开来,将来设计修改也不好做扩展和迁移
设计成嵌套对象的方式,只是方便管理和维护,当然在团队中也可以根据其他考虑,比如序列化性能等,设计成拍平属性。
值对象和充血模型有冲突吗?
这个问题,我觉得很多博客都会认为,值对象就是贫血模型,不会有业务逻辑,其实我个人认为,无论是实体还是值对象,它都是业务的载体,在有业务的地方,我们就应该遵循业务内聚的原则,尽量让模型充血,而不是将值对象的逻辑放在service层。比如上述例子中的地址:需要验证一个地址合法是否合法?此时仍然可以在地址对象中实现验证地址的逻辑,同理对于发件人和收件人的地址我们就可以复用了。所以我仍然是建议将业务逻辑内聚,遵循模型设计高内聚的原则。
实体和值对象该怎么选择?
对于实体还是值对象,它们都是DDD设计中最底层的实现,一起为业务领域服务的。我们在设计时,到底根据什么样的原则将业务模型设计为实体,什么时候设计为值对象呢?
我认为,这还是需要从业务的角度出发,比如在订单领域中,我们的核心领域是解决用户下单后我们的订单数据,此时的地址信息可以是一个值对象,因为它是不可修改的,并且是唯一存在的,是一个从整体替换的;但是在用户领域中,它的收获地址信息,是业务核心关注的方向,此时是存在修改和多个收获地址的场景的,那么此时设计成实体,我们可以根据唯一标识符去修改,维护和管理地址信息。
所以,**根据业务的原则,我们可以考虑将业务模型设计成实体还是值对象,它们存在的最大区别是:是否存在业务的唯一标识符。**我们需要根据业务的模型和方向来最终确定我们的模型设计,存在管理的领域模型建议设计为实体,只存在查询或者可以整体替换的领域模型建议设计为值对象。
这些模型的落地,为什么我们没有数据库设计?
我们的业务模型始终会落地到数据库DB中,数据库又分为关系型数据库和非关系型数据库,它们的存在是否会影响我们的业务模型呢?
答案肯定是不影响的,我们可以选择非关系型的数据库MongoDB来存储订单数据,存储为一个Json对象,也可以使用关系型数据库Mysql存储我们的订单数据,使用表关联join设计为一个模型。
《架构整洁之道》中说到:这些都只是技术细节,数据的组织结构,数据的模型都是架构中的重要部分,但是从磁盘上存储、读取数据的机制和手段却没有那么重要。关系型数据库强制我们将数据存储成表格并且以SQL的方式访问,来提升易用和可读性,但是这些不应该我们的模型设计,总而言之,数据本身才是我们关注的部分,数据库只是一个实现细节。
小节
在本文中,主要还是分析DDD中出现的各种名词,以及存在的原因,建议还是结合前一篇一起理解,这样方能加快理解。首先我们根据软件设计的核心目标中引出问题域,分而治之的思想拆分出子域,从业务的价值和方向又引出核心域、支撑域、通用域,这些的是根据业务的价值维度划分的,我们在设计软件时要紧紧围绕核心域。
进而我们分析了限界上下文,了解到了我们在讨论业务领域统一语言时,需要一定的上下文,这个上下文的边界,我们称作限界上下文;划分限界上下文的过程就是澄清二义性的过程,如果在不同的领域存在业务、概念、语言的二义性时,那么此时两个业务就需要一个限定,来限定二者概念的上下文
后来我们回到战术设计,了解到实体和值对象的区别,实体存在于软件的领域模型中,主要是我们的业务载体,为了标识它,我们往往会根据业务定义一个唯一标识符来标识它。而值对象是一个属性集合,它将多个相关属性组合为一个概念整体。最终还讨论了它们的设计原则,存在管理的信息建议设计为实体,存在查询或者整体替换的信息建议设计为值对象。
在最后,我们始终都没有提及数据库设计,因为数据本身才是我们关注的部分,数据库只是一个实现细节。
今天就到这里了,顺便留一个问题吧:划分限界上下文后,不同的领域上下文,是否就是一个微服务呢?