JDK版本 8u251
解决完成死循环BUG相关的问题,我们来看看ConcurrentHashMap操作相关的多线程计数、查询、删除等方法。
多线程计数
CounterCell
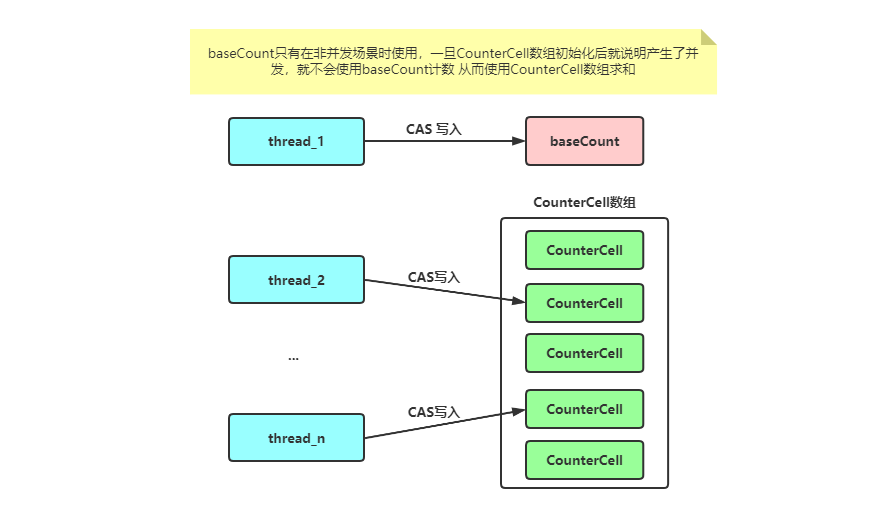
首先回到我们计数的起点,新增元素putVal方法,在新增元素成功后会调用addCount方法,在ConcurrentHashMap中有一个变量baseCount用来记录元素的个数,如果只设置一个变量来存储,当操作线程较少竞争较小的情况下,是没有问题的,但如果操作线程比较多,那么其他线程在更新元素个数时一定会产生大量竞争,那么此时就会转而使用CounterCell数组来进行计数。
可以画张图理解下:
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
CounterCell是一个内部使用volatile修饰long值的包装类,使用了 @sun.misc.Contended,注释上说改编自LongAdder和Striped64,这里我们可以简单了解下缓存行填充和LongAdder的思想。
伪共享
数据在缓存中不是以独立的项来存储的,如不是一个单独的变量,也不是一个单独的指针。缓存是由缓存行组成的,缓存行是2的整数幂个连续字节, 一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时, 如果这些变量共享同一个缓存行,多线程修改时同一个缓存行时,就会相互失效对方的缓存行,无意中影响彼此的性能,这就是伪共享。
可以理解到,如果不加缓存行填充,无意可能极大降低性能。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免操作热点加载到同一个缓存行。当然,也可以使用 @sun.misc.Contended这个注解来避免伪共享,原理是在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。
这里我也进行了相关测试,如果产生伪共享性能将差距3倍多。代码在github上,有兴趣可以自行下载测试。
LongAdder类
LongAdder是一个支持并发操作的原子数类,简单说是AtomicLong的升级版本。LongAdder解决了AtomicLong在高并发场景下操作同一个变量自旋失败性能骤降的痛点。
LongAdder继承自Striped64,Striped64内部有base、cells数组、cellsBusy三个基础变量,LongAdder的值其实就等于base加上cells数组内的value值。cellsBusy是cells初始化,扩容以及创建新的Cell的标志位。
/**
* Adds the given value.
*
* @param x the value to add
*/
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
代码逻辑比较清晰,主要这么几步:
- 首先判断cells数组是否为空,如果为空说明没有产生过线程竞争,直接加在base上即可,如果cas成功,就直接返回了
- 如果cells数组不为空或者base竞争失败了,说明当前已经有了线程竞争,这里会使用cells数组中的随机(getPrebe方法获取当前线程唯一随机数,第一次为0)哈希槽位置进行累加计算。
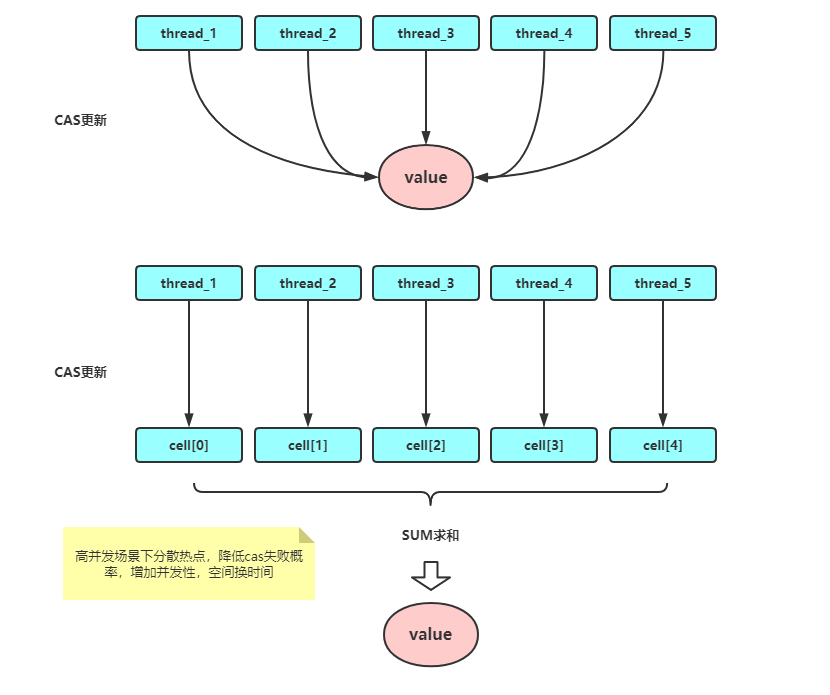
LongAdder所使用的思想就是热点分离,就是将value值分离成一个数组,当多线程访问时,通过hash算法映射到其中的一个数字进行计数。而最终的结果,就是这些数组的求和累加。这样一来,就减小了锁的粒度。
addCount增加计数
回到ConcurrentHashMap操作计数的代码:
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
/**
* baseCount 使用来计数的volatile 变量
* 假如使用cas更新成功 就说明没有其他线程竞争,这里就直接结束了
* 假如更新失败,则说明有其他线程竞争了,则这里在if逻辑中使用CounterCell记录数目
*/
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
/**
* 这里会判断 CounterCell 数组为空
* ThreadLocalRandom.getProbe() 方法 是获取当前线程的唯一随机数 m 是长度-1
* 取与计算就是求模 可以找到在counterCells中对应线程的哈希槽位置
* 如果为空 说明没有初始化
* 如果不为空,则在自增counterCells 数组对应的哈希槽位置自增,如果自增成功则返回
* 如果自增失败 说明多线程竞争,就会统一进到fullAddCount方法中,以此来完成+1的操作
* uncontended 是标记是否发生了竞争
*/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 在fullAddCount方法中会完成最终的计数工作
fullAddCount(x, uncontended);
/**
* 这里 自增计数后,直接返回了 没有去判断是否扩容
* 个人理解 这里因为是高并发场景 直接返回 保证效率 不再去扩容
*/
return;
}
/**
* 这里的小于0说明是清除元素 不需要进行扩容 直接返回
*/
if (check <= 1)
return;
// 否则重新计算计数
s = sumCount();
}
// 扩容逻辑折叠
...
}
简单描述一下这里做的事情:
- 尝试使用cas的方式更新baseCount的计数,这里的baseCount就是一个非并发场景下的计数值,如果CounterCell数组不为空,则说明有竞争,就不会再使用它了。
- 使用ThreadLocalRandom.getProbe()生成当前线程的唯一随机数,并且通过快速求模的方式计算得到CounterCell数组的下标,如果不为空,则尝试更新CounterCell的value值,更新失败或者不存在等,都会使用fullAddCount来计算计数
- fullAddCount方法执行完成后直接返回,这里猜测是在因为在高并发场景下(因为两次CAS失败),保证效率,扩容可以等到竞争小一些时执行。
fullAddCount方法
fullAddCount方法主要对CounterCell数据进行初始化、赋值、扩容等。
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
/**
* ThreadLocalRandom.getProbe == 0说明这个线程还没有初始化过
* 则会调用ThreadLocalRandom.localInit进行初始化 拿到对应线程的惟一数
*/
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
// 记录冲突标志 是否需要扩容 如果为true 则代表需要扩容
boolean collide = false; // True if last slot nonempty
// 这里是一个死循环
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
/**
* 这里是在判断cell数组是否发生过初始化,如果初始化 n = as.length 会大于0
* 第一次进来 显然没有
*/
if ((as = counterCells) != null && (n = as.length) > 0) {
/**
* 如果 找到次数的哈希槽为空,那么就新建一个CounterCell
*/
if ((a = as[(n - 1) & h]) == null) {
// 减小自旋锁的临界区 因为获取volatile 要比 cas的方式快
if (cellsBusy == 0) { // Try to attach new Cell
CounterCell r = new CounterCell(x); // Optimistic create
/**
* cellsBusy 是一个锁的标志位,为0说明无锁,1有锁 其他线程正在操作
* 如果为0 则使用cas的方式设置为1
*/
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
// 双重检查
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
// 将新建的counterCell放入对应的哈希槽中
rs[j = (m - 1) & h] == null) {
rs[j] = r;
// 创建成功
created = true;
}
} finally {
// 释放锁
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
// 到这里说明有其他线程操作 标记不是cas的方式失败的 避免进入扩容逻辑
collide = false;
}
// 说明抢占的位置不为空 且这个值是外面传入的,代表上一次操作操作失败了
else if (!wasUncontended) // CAS already known to fail
// 继续循环
wasUncontended = true; // Continue after rehash
// 如果不为空 则使用cas的方式增加对应位置的value值 如果成功则返回
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
/**
* 这里n >= NCPU 代表是否是到最大值,NCPU是cpu虚拟核心数
* counterCells 毕竟不会太大 够用即可
* counterCells != as 说明有其他线程操作 扩容了
*/
else if (counterCells != as || n >= NCPU)
collide = false; // At max size or stale
/**
* 说实话 这里写的挺不让人好理解的,如果上面条件都是false了
* 简单说 给一次尝试的机会,如果下次还是false 即竞争太大,就会进入扩容的逻辑
*/
else if (!collide)
collide = true;
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
// 加锁 进入扩容逻辑
try {
// double check
if (counterCells == as) {// Expand table unless stale
// 大小为当前的两倍
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
// 释放锁
cellsBusy = 0;
}
// 标记 下次不需要扩容
collide = false;
continue; // Retry with expanded table
}
// 每次循环都会重新生成新的随机数 毕竟哈希槽是廉价的 不需要查询
h = ThreadLocalRandom.advanceProbe(h);
}
/**
* 如果 没有进行初始化,那么标记正在初始化 cellsBusy cas的方式设置为1
* 标记正在初始化
*/
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
/**
* double check
* 如果线程竞争多,在A线程刚刚初始化完成后,会将cellsBusy修改为0,此时
* counterCells已经不为空了,需要二次判断
*/
if (counterCells == as) {
// 初始化长度为2的数组
CounterCell[] rs = new CounterCell[2];
// 如果长度为2 快速求模的方式就是 & 1 了
// 这里直接创建时为counterCell的value赋值
rs[h & 1] = new CounterCell(x);
// 本地变量操作完成后才会赋值volatile 变量
counterCells = rs;
init = true;
}
} finally {
/**
* 在最后更新cellsBusy 为0标记 初始化 完成
*/
cellsBusy = 0;
}
// 如果为创建成功 直接返回
if (init)
break;
}
/**
* 这里就是在抢占 创建 cell数组时失败了 尝试下自旋写入 baseCount
* 万一成功了就直接返回
*/
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
fullAddCount方法挺长的,不过逻辑还是比较好理解,主要有以下几步:
- 如果ThreadLocalRandom.getProbe()没有初始化过,那么就执行初始化
- 判断是否初始化过counterCells数组,如果没有初始化过,那么就会加锁(cellsBusy设置为1)进行初始化长度为2的数组,并根据当前线程的随机数设置一个新的counterCell在对应哈希槽位置
- 判断初始化抢占失败,会再尝试一次更新baseCount的值,如果成功会直接返回
- 判断已经初始化过,那么主要有这么几步
- 判断当前线程随机数的哈希槽位是否为空,如果为空,那么尝试使用cas的方式设置新的counterCell,并且这里会优先使用cellsBusy锁
- 判断当前线程随机数的哈希槽位不为空,那么就会使用cas的方式累加当前哈希槽的值,如果操作成功也会直接返回
- 如果上面都抢占失败,会调整哈希参数的值,重新设置值
- 如果仍然失败,那么说明竞争比较大,会对counterCell数组进行扩容,最大值为当前机器的虚拟核心数
ConcurrentHashMap中的计数思想来自于LongAdder,数据结构和扩容等操作思想是类似的,降低热点冲突的概率,从而增大并发能力。
size方法
最后我们来看下,ConcurrentHashMap的求和方法。
public int size() {
// 因为是long 防止溢出
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
// 注意 这里是一个近似值,如果在计算时,有其他线程进来操作了元素,实际上是不准确的
CounterCell[] as = counterCells; CounterCell a;
// 这里会优先使用baseCount 的值 如果counterCells没有初始化 过 说明没有线程竞争
long sum = baseCount;
if (as != null) {
// 如果初始化 则把counterCells所有不为空的节点加起来就是总数了
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
上面两个方法负责更新和记录总数到baseCount和counterCells数组中,这里只是将总数求和即可。
查询方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 这里直接调用了key的hashCode方法计算哈希值,如果key为null时会报空指针异常
int h = spread(key.hashCode());
/**
* 因为table是懒加载的,如果为空说明未初始化 直接返回null即可
* 如果对应桶位置也为空 说明table中没有值 直接返回
*/
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果根节点就是需要找的值,那么判断hashcode和equals方法相同就会直接返回
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
/**
* 如果eh小于0 有红黑树节点、扩容中节点ForwardingNode、预留节点ReservationNode
* 这里会调用他们各自的find方法
*/
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 大于0 说明是普通的链表节点
while ((e = e.next) != null) {
// 普通节点就是循环直接查找了
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
查询逻辑还是比较清晰的,判断是否初始化,如果未初始化肯定为null了直接返回;接着会判断该桶位置是否有节点,如果没有说明也没有存储过;接着才会判断当前桶节点的类型,如果大于0说明是普通链表节点,直接循环即可。如果小于0,则需要调用其自己的find方法,主要有红黑树节点TreeNode、扩容中节点ForwardingNode、预留节点ReservationNode,这里我们展开细看一下。
ForwardingNode扩容节点
/**
* A node inserted at head of bins during transfer operations.
*/
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {
/**
* 寻找ForwardingNode 是在nextTable上面查找的,
* 迁移操作时,可能触发下次迁移,所以兼容扩容查找的场景要使用nextTable
* 此处需要注意的是:此处使用的是新的nextTable计算桶,可能这个桶还没有迁移
* 也是为空的,所以get方法在多线程操作的场景下不是一定准确的
* 当然,下次再查询get一次就会有了
*/
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
// 如果key为null 或者对应哈希桶也为null 直接返回
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
/**
* 如果 要查询的就是这个节点 直接返回
*/
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
/**
* 这里会判断 是否是小于0 如果小于0 说明在迁移过程中发生了二次迁移
*/
if (eh < 0) {
if (e instanceof ForwardingNode) {
/**
* 这里是防止在查询时又发生了二次迁移,即查询时不加锁的,每个线程的
* 时间片到了 就会等到其他线程执行,这里在遍历节点时,也会出现其他完成了
* 扩容,进而线程put元素 导致了此时发生二次扩容
*/
tab = ((ForwardingNode<K,V>)e).nextTable;
// 这里是直接查询新的哈希表
continue outer;
}
else
// 如果是红黑树或者其他节点,就直接执行他们的查询方法
return e.find(h, k);
}
// 如果不是需要查询的节点,查询下一个节点
if ((e = e.next) == null)
return null;
}
}
}
}
ForwardingNode节点查询是比较复杂的,需要兼容二次扩容场景,主要查询逻辑有:
- 使用nextTable查询,虽然可能会导致查询失败,但是多线程操作本身就不需要同步执行,扩容后仍然是可以查询到的
- 循环对应哈希桶的节点,如果头节点是需要查找的节点那么直接返回
- 如果是当前节点的hash值是小于0的,那么需要判断是否是扩容节点还是红黑树节点等,如果是扩容节点,那么需要使用新的nextTable继续查询(查询时发生了二次扩容);如果是其他节点,调用它们的find方法即可。
- 如果是普通节点,即hash值大于0,则遍历查询即可
ReservationNode预留节点
/**
* A place-holder node used in computeIfAbsent and compute
*/
static final class ReservationNode<K,V> extends Node<K,V> {
ReservationNode() {
super(RESERVED, null, null, null);
}
Node<K,V> find(int h, Object k) {
return null;
}
}
预留节点是不能进行查询的,标记这个值正在计算
删除方法
删除有两个remove和clear方法,我们先看下remove方法
remove方法
public V remove(Object key) {
return replaceNode(key, null, null);
}
remove方法,调用的replaceNode方法,不过只传入了key,value为null。
final V replaceNode(Object key, V value, Object cv) {
// 计算哈希值
int hash = spread(key.hashCode());
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)
// 如果查询不到 就什么都不做 直接返回
break;
else if ((fh = f.hash) == MOVED)
// 和putVal方法类似,如果判断当前桶正在迁移 那么就回去帮助迁移
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
// 删除也是锁住了头结点 以防止其他线程操作
synchronized (f) {
// double check
if (tabAt(tab, i) == f) {
if (fh >= 0) {
// fh大于0 说明是普通节点
validated = true;
for (Node<K,V> e = f, pred = null;;) {
K ek;
/**
* 这里和put方法不同的是,如果查询到了相关的节点
* 还会需要判断传入的cv是否为空
* 如果不为空 则需要判断cv的值 传入的cv是否和原值相同,如果相同才
* 会进行操作
*/
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
V ev = e.val;
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
// 判断如果value不为空才会进行替换
if (value != null)
e.val = value;
// 否则是进行删除 需要将上一个节点pred 的next更改
// 即 上一个next 为下一个next的值 不再连接当前节点
else if (pred != null)
pred.next = e.next;
else
// pred 为空 说明是第一个节点 那么需要更改桶的头结点
setTabAt(tab, i, e.next);
}
// 如果未找到需要删除的元素相同cv值 那么 就会返回null
break;
}
pred = e;
// 循环下一个节点
if ((e = e.next) == null)
break;
}
}
// 如果是红黑树节点
else if (f instanceof TreeBin) {
validated = true;
// 折叠 这里不展开
}
}
}
// 如果是上面两种节点类型
if (validated) {
if (oldVal != null) {
if (value == null)
// 如果value 为null代表删除 这里需要减计数器的值
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
}
replaceNode操作和putVal有些类似,判断是在扩容时,仍然会帮助扩容,但不同的地方会判断传入的删除值cv是否不为空(为空代表不判断)是否和对应的值相等,如果不相等,则不会进行操作直接返回null。
结束时,会判断传入的value是否为null,如果为null代表删除节点,则会递减计数器的值。
clear方法
clear方法就是删除所有元素,这里会依次遍历所有桶进行加锁删除
public void clear() {
long delta = 0L; // negative number of deletions
int i = 0;
Node<K,V>[] tab = table;
// i是桶的索引 从第0个开始
while (tab != null && i < tab.length) {
int fh;
// 如果头结点为空 那么直接跳过
Node<K,V> f = tabAt(tab, i);
if (f == null)
++i;
else if ((fh = f.hash) == MOVED) {
// 如果正在扩容,那么也会去帮助扩容 并且重置i
tab = helpTransfer(tab, f);
i = 0; // restart
}
else {
// 加锁
synchronized (f) {
// double check
if (tabAt(tab, i) == f) {
Node<K,V> p = (fh >= 0 ? f :
(f instanceof TreeBin) ?
((TreeBin<K,V>)f).first : null);
// 这里会遍历所有链表或者红黑树节点,记录delta数量
while (p != null) {
--delta;
p = p.next;
}
// 通过直接设置桶的头结点来进行删除,这里会给i自增
setTabAt(tab, i++, null);
}
}
}
}
// 如果不为空,则需要进行更新计数器的值
// check 为-1是不会进行扩容的
if (delta != 0L)
addCount(delta, -1);
}
clear方法做的事情就是清除每个桶的头结点了,在遇到扩容节点时也会进行协助扩容。并且在最后,如果发现操作元素数不为0也会更新计数器的值。
总结
至此,ConcurrentHashMap的主要操作逻辑已经分析完成,一路走下来,时间漫长但也是收获颇丰的。相见恨晚,ConcurrentHashMap简直就是标准的多线程教科书,特别是多线程扩容、计数部分,使用分段扩容、缓存行填充、热点分离等思想,都是值得反复研读的,甚是精彩。