并发问题的背景
这里我们先从最源头,想想volatile的存在为了解决什么样的问题?
随着CPU、内存、IO设备不断更新发展,有一个核心矛盾一直存在:CPU、内存、IO三者的速度差距
为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:CPU 增加了缓存,以均衡与内存的速度差异;操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;编译程序优化指令执行次序,使得缓存能够得到更加合理地利用
CPU缓存一致性协议
CPU在内存之间增加了 Cache,CPU 将数据从 memory 读取到 Cache中,在 Cache 中对数据进行读写的速度是很快的,这样就提高了性能
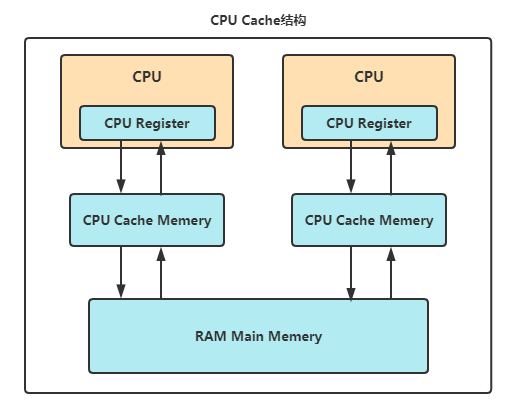
在有多个核的处理器的处理器中,每个核都有自己的Cache,而如何确保多个核的cache内容的一致则是一个很容易遇到的问题,MESI协议就是一个专门用来解决Cache一致性的协议
MESI协议名字的由来是由其描述的四个cache状态组成的,分别是M(modified)、E(exclusive)、S(shared)和I(invalid)。各个状态的描述具体如下:

MESI实际上是标记CPU缓存行的状态,是一种状态机的体现。这里推荐一个学习工具,能看到 Cache 是怎么在这四个状态之间流转 MESI Cache Coherency Protocol
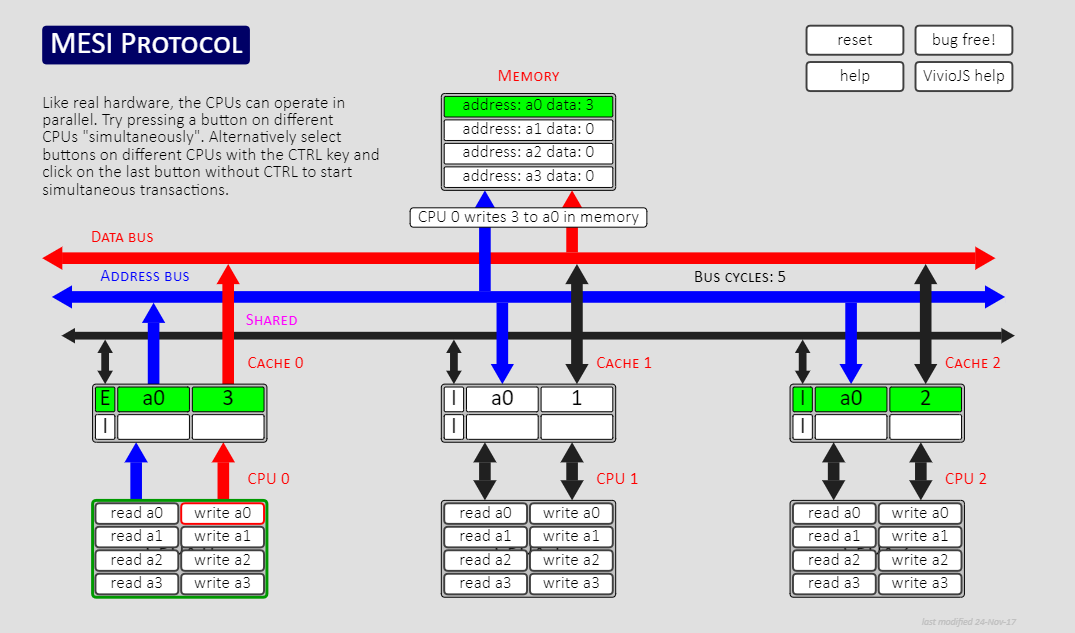
结合实际显示可能会更好理解,图中显示了三个CPU的缓存行,每个缓存行最左边字母就是当前的缓存行状态,CPU0因为刚刚修改了缓存行的值为3并写入主存,CPU0当前缓存行变为独占态(E),并通知其他CPU此缓存行为失效(I),如果此时CPU0对独占态(E)数据进行修改就会变成已修改(M),其他CPU读取之后CPU0中的缓存行就会变成共享(S)
真实的 MESI 协议非常复杂,MESI 因为是缓存之间维护数据一致性的协议,所以它所有请求都分为两端,请求来自 CPU 还是来自 Bus(这里只做简单介绍)
内存屏障 Memory Barrier
Store Buffer
现在假设CPU0要写入数据到内存中,那么此时有两种情况:
- 当前CPU的缓存中有目标数据的缓存行,处于Shard状态
- 当前CPU的缓存没有目标数据的缓存行
第一种情况下,CPU 0 只要发送 Invalidate 消息给其它 CPU 即可(如果其他CPU没有此数据的缓存行,则不会做此事件)。收到所有 CPU 的 Invalidate Ack 后,CPU0当前 Cache Line 可以转换为 Exclusive 状态。第二种情况下,CPU 0 需要发送 Read Invalidate 到所有 CPU,拥有最新目标数据的 CPU 会把最新数据发给 CPU 0,并且会标记自己的这块 Cache Line 为无效 (假如其他CPU也没有目标数据的缓存行,则不会发送消息给其他CPU)
无论是 Invalidate 还是 Read Invalidate,CPU 0 都得等其他所有 CPU 返回 Invalidate Ack 后才能安全操作数据,这个等待时间可能会很长。因为 CPU 0 这里只是想写数据到目标内存地址,它根本不关心目标数据在别的 CPU 上当前值是什么,所以这个时候 Store Buffer 就产生了
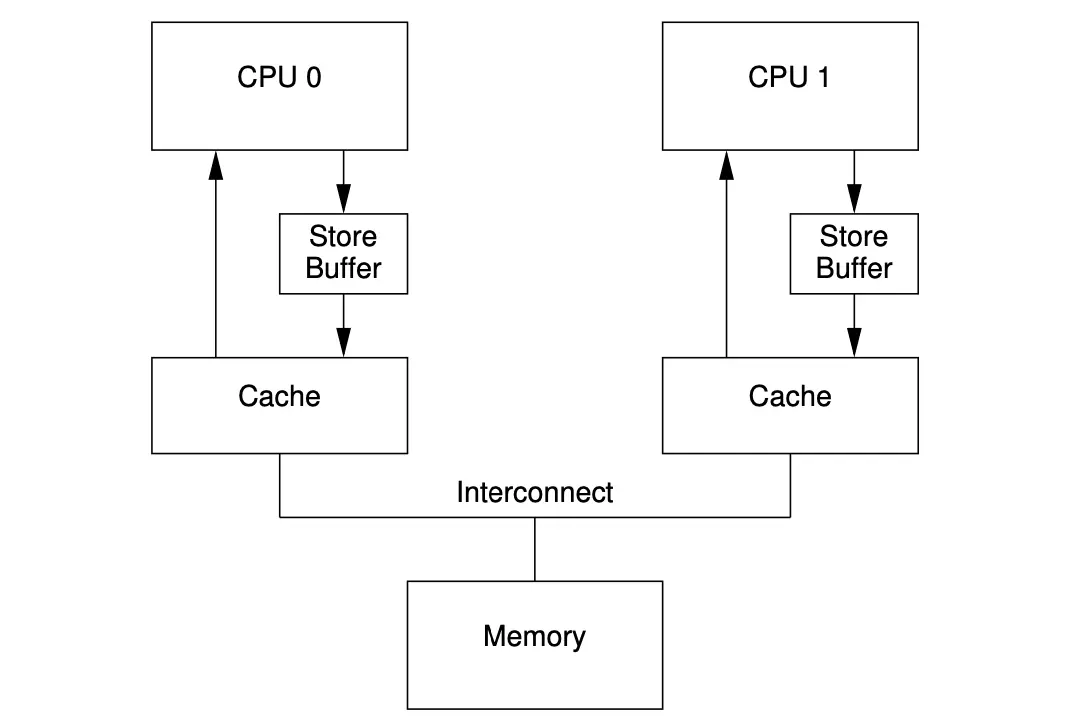
每次写数据时发送 Invalidate 去其它 CPU,同时将新写的数据内容放入 Store Buffer。接着就去执行别的指令,等到所有 CPU 都回复 Invalidate Ack 后,再将对应 Cache Line 数据从 Store Buffer 移除。这样就避免了因为等待其他CPU响应而产生的空等待
当然还可以兼容第二种情况,当Write miss(目标数据不在当前cpu缓存行中)时,正常来说需要等待数据从 Memory 加载到 Cache 后 CPU 才能开始写,那有了 Store Buffer 的存在,如果待写内存现在不在 Cache 里可以不用等待数据从 Memory 加载,而是把新写数据放入 Store Buffer,接着去执行别的操作,等数据加载到 Cache 后再把 Store Buffer 内的新写数据写入Cache
因为上面两种情况,都是由于写到Store Buffer中,实际上没有写入主存,就去执行了其他操作,其他CPU不知道缓存的数据发生了更改,而导致的内存不一致问题,产生指令重排:相当于下一次指令重排到了当前写入数据之前
Store Forwarding
引入Store Buffer之后还产生了新的问题,单个 CPU 在顺序执行指令的过程中,有可能出现,前面的已经执行写入变更,但对后面的代码逻辑不可见
比如现在有这个代码,a 一开始不在 CPU 0 内,在 CPU 1 内,值为 0。b 在 CPU 0 内
a = 1;
b = a + 1;
assert(b == 2);
CPU 0在写入a=1时,发现CPU 0没有a的缓存,写入a是直接操作的Store Buffer,之后需要发送 Read Invalidate 去 CPU 1,而没有等待CPU 1响应,接着CPU 0去执行 b = a + 1,此时缓存行在CPU 1中还是 0,如果CPU 0直接使用缓存还是内存中的值都是0导致b == 1,assert失败;所以为了解决此问题,引入了Store Forwarding
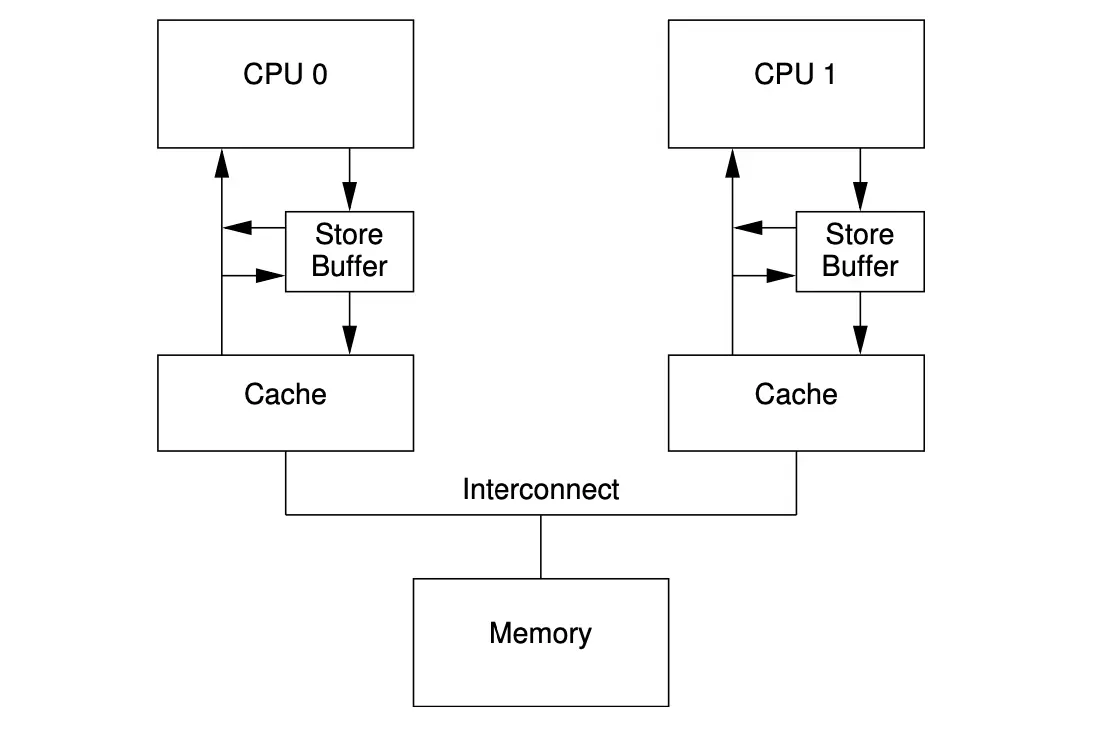
此时同一个 CPU 而言,在读取 a 变量的时候,如若发现 Store Buffer 中有尚未写入到缓存的数据 a,则直接从 Store Buffer 中读取。这就保证了,逻辑上代码执行顺序,也保证了可见性
写屏障 Write Barrier
这里我们通过一个案例来了解写屏障的作用,代码如下:
// CPU 0 执行 foo(), 拥有 b 的 Cache Line
void foo(void)
{
a = 1;
b = 1;
}
// CPU 1 执行 bar(),拥有 a 的 Cache Line
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
CPU 0执行a = 1 发现CPU 0并没有缓存行,所以发送Read Invalidate去获取 a 缓存行的修改权,此时直接将a的新值修改在store buffer,直接执行b = 1,因为有b的缓存行所以直接修改,并且处于 Exclusive 状态
此时CPU 1 发送Read消息读取 b 的值,从缓存行加载,发现 CPU 0 已经修改了b的值,读取b = 1,跳出循环;假设到此都没有接收到CPU0发送的Read Invalidate消息,那么此时的 a 仍然是缓存行中的0初值,所以此处assert就会失败
上面的问题就是因为Store buffer的存在导致第二个写操作被指令重排到第一个之前,从而导致可见性问题。解决这类问题的方式就是增加写屏障(Write Barrier),将 Write Barrier 之前所有操作的 Cache Line 都打上标记,作用就是Barrier之后的写指令不能直接操作Cache而是也需要进入Store Buffer中,等 Store Buffer 内带着标记的写入因为收到 Invalidate Ack 而能写 Cache Line 后,这些没有打标记的写入操作才能写入 Cache Line,从而严格意义上来保证添加Barrier屏障之前的写指令不允许被重排
相同的代码,增加写屏障后:
// CPU 0 执行 foo(), 拥有 b 的 Cache Line
void foo(void)
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),拥有 a 的 Cache Line
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
此时对 CPU 0 来说,a 写入 Store Buffer 后带着特殊标记,b 的写入也得放入 Store Buffer,写入b数据缓存行的指令不允许先于写入a的指令先执行,表示强制让所有的。
这样如果CPU 1没有返回 CPU 0 对a操作的Invalidate Ack时CPU 0对b的修改对CPU 1就不可见,从而 CPU 1读取的b 会一直为0;直到响应对a数据缓存行的修改后(修改a缓存行为无效),CPU 0才会继续执行,接着CPU 1跳出循环再次读取a的新值即为1
Invalidate Queues
Store Buffer的长度是有限的,当某一段时刻CPU 操作的缓存行均被其他CPU持有,那么当前CPU需要等待一系列的 Invalidate Ack消息后才能将这批消息刷入缓存行
当Store Buffer超过最大变更容量后,此时CPU又需要等待Store Buffer排空后执行。所以设计者为了减少 invalidate ack产生的延时问题,就引入了Invalidate Queues:CPU 接收到 invalidate 消息,立马响应invalidate ack,而cache line 此时也并非强制要求马上失效,只要确保最终会失效即可
进而,基于这个思路,每个CPU 都拥有的 Invalidate Queues 结构从此形成
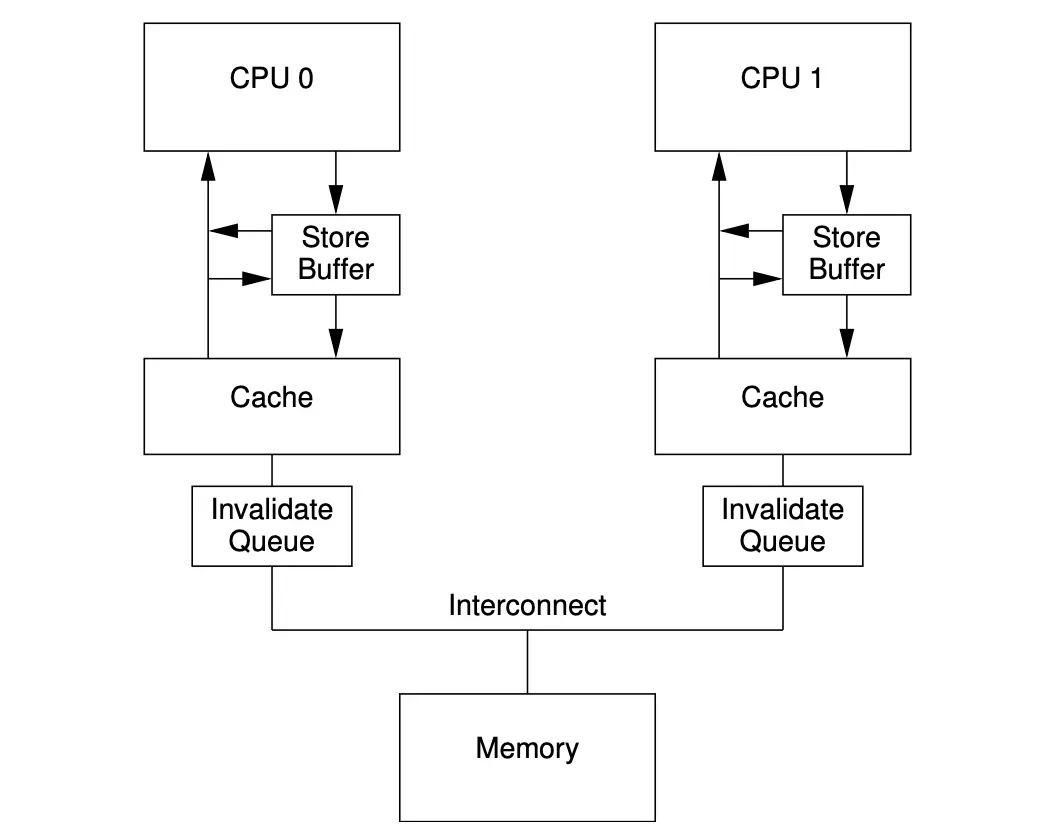
每个 CPU 都有一个 Invalidate Queue,当CPU收到Invalidate 消息后放入队列,之后立马响应Ack消息。以把需要失效的数据物理地址存储起来,根据这个物理地址,我们可以对缓存行的失效行为 “延后执行”
读屏障 Read Barrier
当然上面的设计有副作用,就是当前Cache Line因为Invalidate 请求被放入Invalidate Queue后,CPU还操作当前Cache Line的话就会是旧数据,CPU也不能直接去Invalidate Queue中查看当前缓存行是否存在;当然要解决这个问题,那么得先把 CPU 自己的 Invalidate Queue 清理干净,或者至少有办法让 Cache 确认一个 Cache Line 在自己这里状态是非 Invalidate 的
此时Read Barrier就出现了,它的作用是:是标记 Invalidate Queue 上的 Cache Line,之后继续执行别的指令,直到看到下一个 Load 操作要从 Cache Line 里读数据了,CPU 才会等待 Invalidate Queue 内所有刚才被标记的 Cache Line 都处理完才继续执行下一个 Load
同样的代码,我们在分析下:
// CPU 0 执行 foo(), a 处于 Shared,b 处于 Exclusive
void foo(void)
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),a 处于 Shared 状态
void bar(void)
{
while (b == 0) continue;
assert(a == 1);
}
- CPU 0 将 a = 1写入Store Buffer后,向CPU 1 发送Read Invalidate 消息
- CPU 1直接将其放入了Invalidate Queue队列,响应CPU 0 Ack消息
- CPU 0 继续执行,将 b = 1写入缓存
- CPU 1 读取CPU 0 刚刚写入的 b = 1新值,跳出循环
- 此时 a = 1失效的消息仍然在CPU 1 的Invalidate Queue中,并没有真正失效 a 所在缓存行,那么此时CPU 1读取的 a = 0 会导致 assert 失败
解决方案是增加 Read Barrier
// CPU 0 执行 foo(), a 处于 Shared,b 处于 Exclusive
void foo(void)
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),a 处于 Shared 状态
void bar(void)
{
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
有了 Read Barrier 后,在执行smp_rmb时会标记Invalidate Queue的缓存行,下一个指令操作 a 发现已经被标记,开始失效所有之前标记的缓存行,则会真的失效 a 所在缓存行,从而发送Read 消息给CPU 0,读取 a 所在缓存行的最新值,assert 成功
除了 Read Barrier 和 Write Barrier 外还有合二为一的 Barrier。作用是让后续写操作全部先去 Store Buffer 排队,让后续读操作都得先等 Invalidate Queue 处理完
Java 内存模型
Java为了能在不同架构的CPU上执行,也抽象了一套自己的内存模型,定义了线程和内存的交互模型,可见性问题等
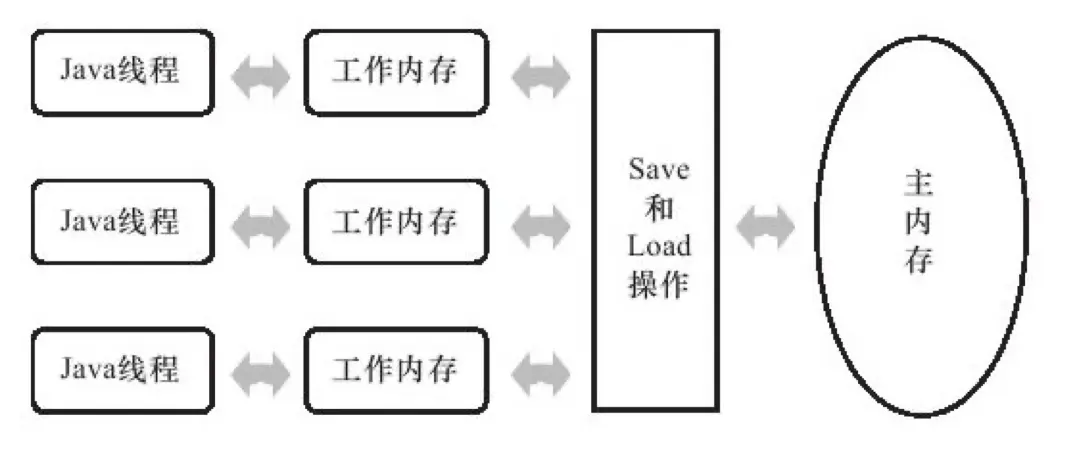 (图片来自《深入理解 Java 虚拟机》)
(图片来自《深入理解 Java 虚拟机》)
从内存模型一词就能看出来,这是Java对真实CPU硬件的模拟。图中 Java 线程对应的就是 CPU,工作内存对应的就是 CPU Cache,Java 提炼出来的一套 Save、Load 指令对应的就是缓存一致性协议,就是 MESI 等协议,最后主内存对应的就是 Ram Memory
JMM模型完善于 JSR-133,这里推荐学习Doug Lea之前写的Cookbook The JSR-133 Cookbook for Compiler Writers
JVM的内存屏障(Memory Barrier)
Java根据前后读(Store)写(Load)操作的不同,分为了四种内存屏障:

当然还建议看一下官方注释,这里讲的更仔细 MemoryBarriers.java
StoreLoad 为什么能实现其它 Barrier 的功能?
这里我们先看一下StoreStore和LoadLoad,它们只是限制读和写,即只有一次内存交互。而LoadStore和虽然也有读写限制,但实际上它限制的是Store2后的写不允许排列到Load1前,并没有对Store2后的可见性做要求,大部分读操作都是比写操作快的,所以Store重排到Load前根据架构不同也比较少见,而StoreLoad则是保证前面的写必须要保证在读之前,即先将修改指令写入Store Buffer,再处理 Invalidate Queue,进行了两次内存交互
在 x86 上,实际只有 StoreLoad 这一个 Barrier 是有效的,因为 x86 上没有 Invalidate Queue,每次 Store 数据又都会去 Store Buffer 排队,所以 StoreStore, LoadLoad 都不需要。x86 又能保证 Store 操作都会走 Store Buffer 异步刷写,Store 不会被重排到 Load 之前,LoadStore 也是不需要的
写入数据之后加一个 写Barrier 去刷缓存到主存,读数据之前加入 读Barrier 去强制从主存读 是否成立?
首先这个说法严格意义上说是不正确的,增加写Barrier 只是让写屏障之后写指令操作Store Buffer保证刷入Cache上,Cache什么时候往主存中写实际上是由缓存一致性协议来决定的,并不是由内存屏障保证的;增加读Barrier 是只是为了标记Invalidate Queue的失效缓存,如果当前缓存行是Shard状态,实际上本身就是可以继续读取,也不需要再从主内存中读取;严格意义上来说,内存屏障保证的是顺序一致性,而缓存一致性由MESI协议保证,这里面的概念不能被混淆
volatile关键字
我们再从volatile语义看下定义:
- 可见性
- 禁止指令重排,volatile的写入不往前排,volatile的读取不往后排
可见性是说线程A操作的volatile变量一定是要被线程B看到,其次是两个指令操作比如:a b 两个变量,b变量是volatile修饰的,那么 a = 1;b = 2这个操作,就需要保证b = 2时 a 一定等于 1,保证了其他线程能看到线程A Store之前的操作
禁止指令重排实际上是为了保证可见性而做的努力,如果不禁止指令重排就无法做到可见性的要求(可以查看上面的代码案例)。volatile变量的写入保证了Store的操作对其他线程可见,volatile变量的读取操作保证了读取操作一定是最新的值,以后的操作可能依赖所以不能往后重排
volatile的底层实现
根据volatile的语义,我们需要保证volatile的变量读写操作需要被其他线程可见,主要有两个情况:
- 写入的 volatile 变量在写完之后能被别的 CPU 在下一次读取中读取到
- 写入 volatile 变量之前的操作在别的 CPU 看到 volatile 的最新值后一定也能被看到;
对于第一点,我们需要做的是:
- 读取 volatile 变量不能使用寄存器,每次读取都要去内存拿
- 禁止读 volatile 变量后续操作被重排到读 volatile 之前
对于第二点,
- 通过写 volatile 变量时的 Barrier 保证写 volatile 之前的操作先于写 volatile 变量之前发生
在Hospot源码中的bytecodeInterpreter.cpp文件中,这个文件又被称作“C++解释器”,被用来解析JVM字节码指令集,我们在里面可以找到_putstatic/_putfield的字节码指令的Hospot解释器的实现
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ztos) {
int bool_field = STACK_INT(-1); // only store LSB
obj->release_byte_field_put(field_offset, (bool_field & 1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
OrderAccess::storeload();
}
cache->is_volatile(),表示如果变量i被volatile修饰,那么为true,接着给变量i的赋值,操作由release_xxx(类型)_field_put方法实现,假设此时为int类型,来看看release_int_field_put方法的实现
inline void oopDesc::release_int_field_put(int offset, jint contents){
OrderAccess::release_store(int_field_addr(offset), contents);
}
// linux_X86 实现 orderAccess_linux_x86.inline.hpp文件中
inline void OrderAccess::release_store(volatile jint* p, jint v) {
*p = v;
}
内部调用了release_store方法,该方法在不同的系统环境中有不同的实现,我们来看看在linux_X86中的实现,这里是直接将v的值放在了p的位置,没有做任何优化。在调用完release_int_field_put之后我们看到还有一个OrderAccess::storeload操作:
inline void OrderAccess::storeload() {
fence();
}
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
这其实就是JVM中一个的内存屏障- storeload屏障的实现,在写入变量后插入一个storeload屏障,也是最重的屏障,保证写入的变量可以立刻对其他线程(CPU)可见
当然在java中,单核就没有什么事了,否则是加上对应的lock前缀,在多处理器环境中,LOCK#信号确保在声言该信号期间,处理器可以独占任何共享内存(因为它会锁住总线,导致其他CPU不能访问总线,不能访问总线就意味着不能访问系统内存)但是,在最近的处理器里,LOCK#信号一般不锁总线,而是锁缓存,毕竟锁总线开销的比较大,它会锁定这块内存区域的缓存并回写到内存,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”(这里对不同的CPU实现不做深入探讨)
DCL单例模式是否真的需要volatile修饰?
// volatile double 检查单例模式
private static volatile DoubleCheckSingleton INSTANCE;
private DoubleCheckSingleton() { }
public static DoubleCheckSingleton getInstance() {
if (INSTANCE == null) {
synchronized (DoubleCheckSingleton.class) {
/**
* INSTANCE 必须要保证是volatile修饰的
* 第一点 保证线程间可见性
* 第二点 禁止指令重排序 通常情况下 new 分为三步
* 1.申请一块内存,其中成员变量赋默认值
* 2.调用类的构造方法,给成员变量赋初始值
* 3.将这块内存区域赋值给栈的相应变量,简单理解就是把new出来的这个对象的地址赋值给o
*
* 如果按照这样进行下去 往往是没有问题的,问题在于jvm底层在某些时候存在“指令重排”的问题
* 这三个步骤的2,3两步是可能调换的。
* 假设高并发场景下,2,3步骤发生了指令重拍,线程A刚刚执行完第三步,但实际上此时的对象还没有
* 初始化,属性还没完成赋值,此时是一个不完整对象,但已经不为null了,那么如果此时线程B进来判断
* 对象不为null直接使用,实际上是有问题的。
*
* 所以这里需要加上volatile关键字,禁止指令重排序,从而保证线程安全。
*/
if (INSTANCE == null) {
INSTANCE = new DoubleCheckSingleton();
}
}
}
return INSTANCE;
}
在网上很多例子上说,因为指令重排序,可能会导致 IdGenerator 对象被 new 出来,并且赋值给 instance 之后,还没来得及初始化(执行构造函数中的代码逻辑),就被另一个线程使用了
实际上,这里也确实存在指令重排的问题,但是在Java 8之后已经被修复了,我们在在Hospot源码中的bytecodeInterpreter.cpp文件可以看到:
CASE(_new): {
// ... 折叠
if (result != NULL) {
// Initialize object (if nonzero size and need) and then the header
// ... 折叠
// Must prevent reordering of stores for object initialization
// with stores that publish the new object.
OrderAccess::storestore();
SET_STACK_OBJECT(result, 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
}
}
// Slow case allocation
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index),
handle_exception);
// Must prevent reordering of stores for object initialization
// with stores that publish the new object.
OrderAccess::storestore();
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
上面代码中,我们可以看到根据是否加载class而构造对象分为快速和Slow构造,但是他们之间都有一句:
Must prevent reordering of stores for object initialization with stores that publish the new object.
而在这段注释下面有一个OrderAccess::storestore()屏障,防止指令重排,保证了设置对象的引用不会发生在初始化之前,所以也就是说,DCL模式下的变量在new关键字内部不会发生指令重排
参考
OpenJDK8 源码
cpu缓存和volatile
内存屏障及其在-JVM 内的应用(上)
内存屏障及其在-JVM 内的应用(下)
Java中的volatile实现原理深度解析以及应用
TSM03-J. Do not publish partially initialized objects